在 AI 大模型行业普遍涨价的大环境下,DeepSeek 却逆势而行,两天内两度降价,甚至将部分服务的价格压至 GPT-5 的 1/50~1/70。这绝非简单的“价格战”,而是一场由硬件、能源、技术三重优势共同驱动的“成本革命”。
要理解这一现象,必须对比行业现状,拆解 DeepSeek 的独特路径,并看清其背后的长期战略意义。
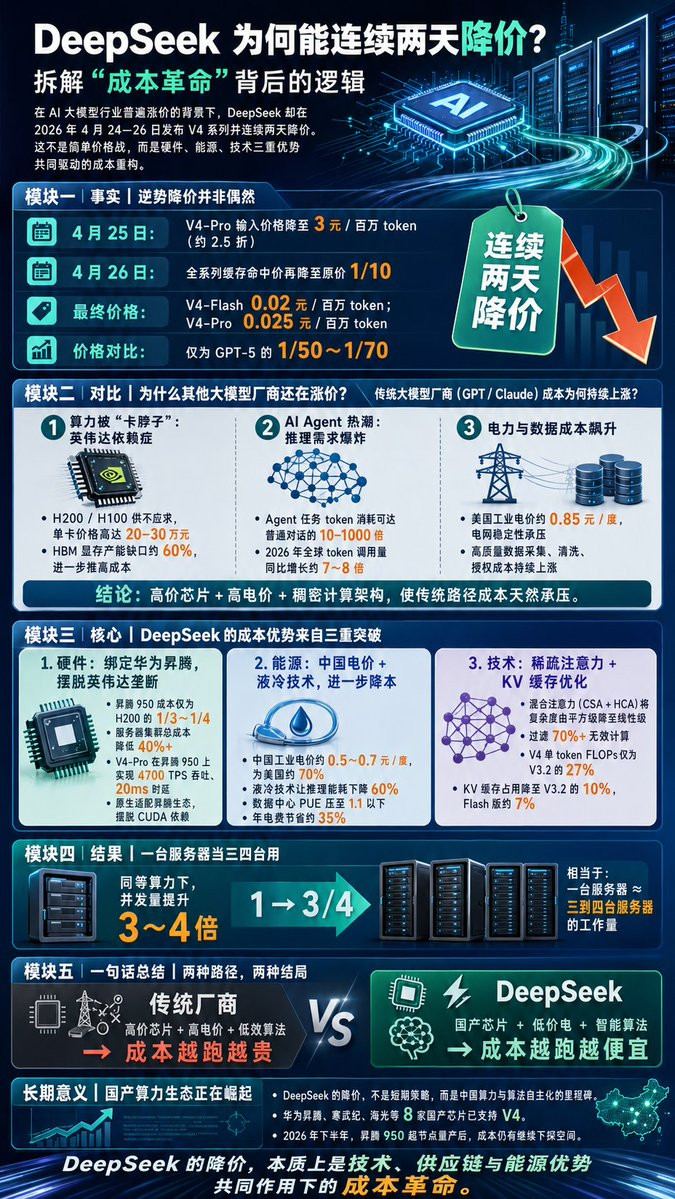
一、事实:DeepSeek 的“逆势降价”并非偶然2026 年 4 月 24–26
在 AI 大模型行业普遍涨价的大环境下,DeepSeek 却逆势而行,两天内两度降价,甚至将部分服务的价格压至 GPT-5 的 1/50~1/70。这绝非简单的“价格战”,而是一场由硬件、能源、技术三重优势共同驱动的“成本革命”。
要理解这一现象,必须对比行业现状,拆解 DeepSeek 的独特路径,并看清其背后的长期战略意义。
一、事实:DeepSeek 的“逆势降价”并非偶然 2026 年 4 月 24–26 日,DeepSeek 发布 V4 系列并连续两天降价:4 月 25 日:V4‑Pro 输入价格降至 3 元/百万 token(2.5 折)4 月 26 日:全系列缓存命中价再砍至原价的 1/10最终价格:V4‑Flash 0.02 元/百万 token,V4‑Pro 0.025 元/百万 token,仅为 GPT‑5 的 1/50~1/70这不是“烧钱换市场”,而是 DeepSeek 的成本结构已发生根本性优化。
二、对比:为何其他大模型厂商(GPT/Claude)成本持续上涨? 全球主流 AI 厂商的成本攀升,主要受三大因素制约:
1. 算力被“卡脖子”:英伟达依赖症芯片短缺:H200/H100 供不应求,单卡价格飙升至 20–30 万元HBM 显存缺口:全球 HBM 产能缺口达 60%,进一步推高成本.
2. AI Agent 热潮:推理需求爆炸Agent 任务的 token 消耗是普通对话的 10–1000 倍2026 年全球 token 调用量同比 +7~8 倍,算力需求“饥渴”3. 电力与数据成本飙升海外电价高企:美国工业电价约 0.85 元/度,电网稳定性存忧高质量数据枯竭:采集、清洗、授权成本持续上涨传统大模型依赖英伟达芯片+高电价+稠密计算架构,成本结构天然承压,涨价是必然。
三、DeepSeek 的成本优势:硬件、能源、技术三重突破
1. 硬件:绑定华为昇腾,摆脱英伟达垄断芯片价格优势:昇腾 950 成本仅为 H200 的 1/3~1/4,服务器集群总成本 降低 40%+性能不输英伟达:V4‑Pro 在昇腾 950 上实现 4700 TPS 吞吐,20ms 时延,媲美甚至超越英伟达平台全球首个原生适配昇腾的顶级大模型,彻底摆脱 CUDA 依赖
2. 能源:中国电价+液冷技术,能耗大幅优化电价优势:中国工业电价 0.5~0.7元/度,为美国的 70%左右。昇腾平台推理能耗 下降 60%,数据中心 PUE 压至 1.1 以下,年电费节省 35%
3. 技术:稀疏注意力+KV 缓存优化,算力效率“质变”混合注意力(CSA+HCA):将计算复杂度从“平方级”降至线性级,过滤 70%+ 无效计算V4 实测效率:单 token 计算量(FLOPs)仅为 V3.2 的 27% KV 缓存占用降至 V3.2 的 10%(Flash 版 7%)同等算力下,并发量提升 3~4 倍,相当于“一台服务器当三四台用”
四、一句话总结:两种路径,两种结局传统厂商:依赖高价芯片+高电价+低效算法 → 成本越跑越贵DeepSeek:采用国产芯片+低价电+智能算法 → 成本越跑越便宜
五、长期意义:国产算力生态的崛起DeepSeek 的降价并非短期策略,而是中国算力+算法自主化的里程碑:国产芯片全面适配:华为昇腾、寒武纪、海光等 8 家国产芯片已支持 V4未来成本仍可下降:2026 下半年昇腾 950 超节点量产,成本还有压缩空间DeepSeek 的降价,是技术、供应链、能源优势的综合体现。